|
Liang Xu (徐良) I'm a final-year PhD student of the joint program between Shanghai Jiao Tong University and Eastern Institute of Technology, Ningbo, supervised by Wenjun Zeng and Xiaokang Yang. I also work closely with Xin Jin and Yichao Yan. Prior to that, I received my B.S. in Computer Science from Nanjing University in 2018, and the M.S. in Computer Science from Shanghai Jiao Tong University in 2021, supervised by Cewu Lu. I was also fortunate to work with Wenjun Zeng and Cuiling Lan as a research intern in Intelligent Multimedia Group at Microsoft Research Asia. Email / Google Scholar / GitHub / Twitter / 知乎 |

|
|
Research
I have broad research interests on human-centered vision, including modeling human motion and human-centric interactions for avatars, embodied intelligence, human behavior analysis and biomedical applications. I'm always open to collaborations. If you're interested in working together, please feel free to reach out. 😊 |
|
Selected Publications & Projects
* denotes equal contribution |
|
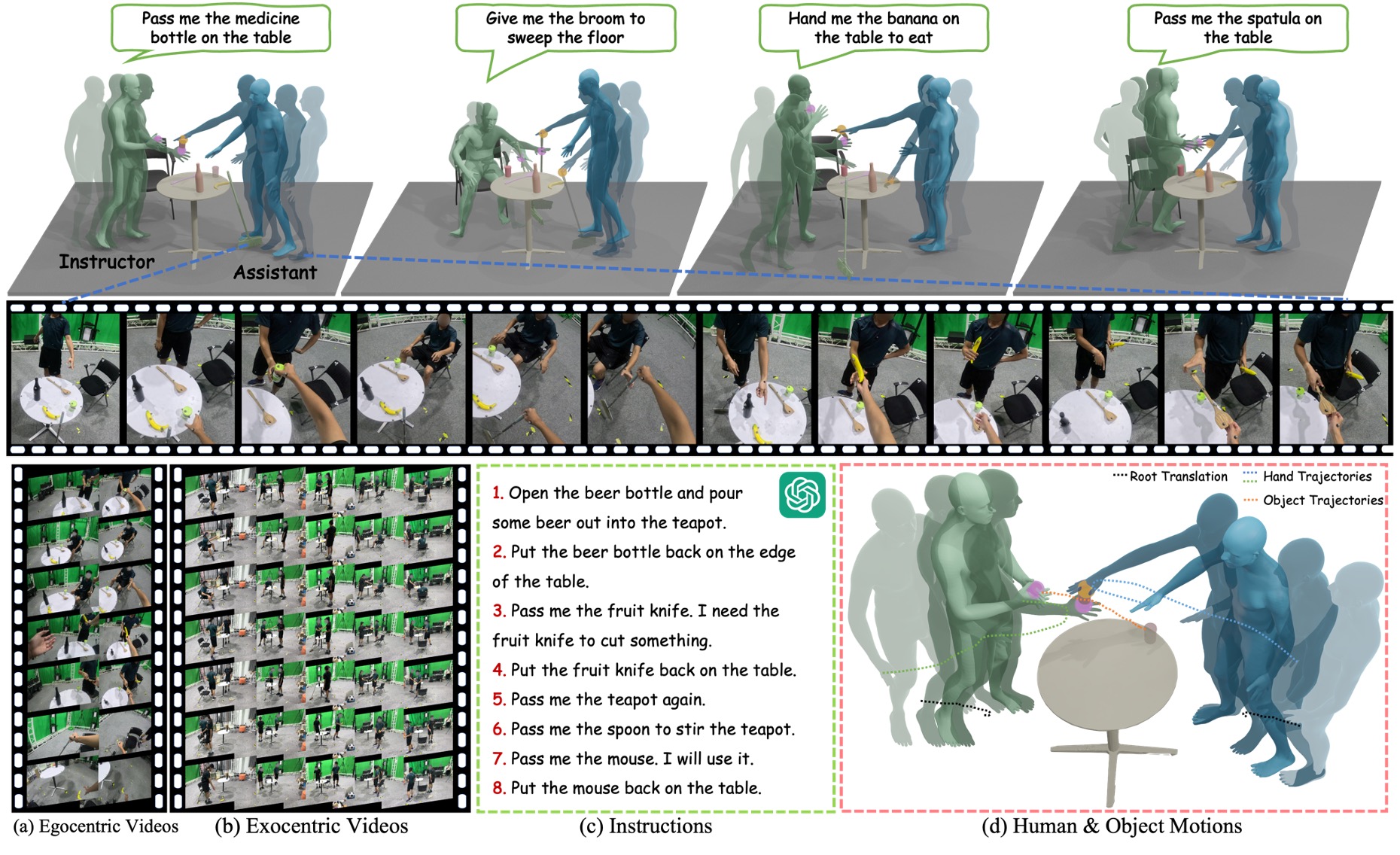
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Liang Xu, Chengqun Yang, Zili Lin, Fei Xu, Yifan Liu, Congsheng Xu, Yiyi Zhang, Jie Qin, Xingdong Sheng, Yunhui Liu, Xin Jin, Yichao Yan, Wenjun Zeng, Xiaokang Yang ICCV, 2025 [Paper] [Project] [Code (Coming Soon)] We aim to explore a unified first-person framework for modeling and benchmarking human–human, human–object, and human–scene interactions within a vision-language-action framework. |
|
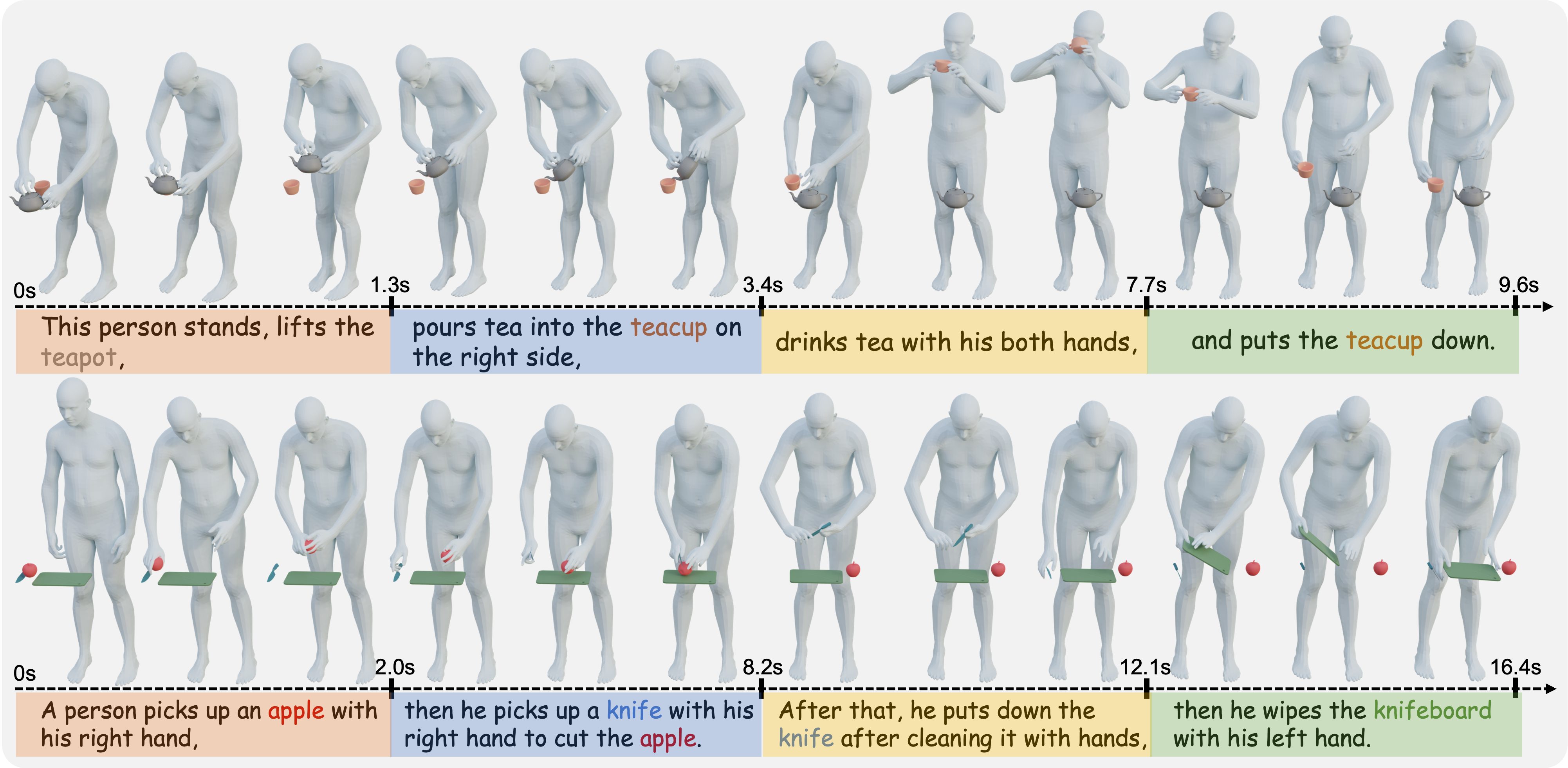
HIMO: A New Benchmark for Full-Body Human Interacting with Multiple Objects
Xintao Lv*, Liang Xu*, Yichao Yan, Xin Jin, Congsheng Xu, Shuwen Wu, Yifan Liu, Lincheng Li, Mengxiao Bi, Wenjun Zeng, Xiaokang Yang ECCV, 2024 [Paper] [Project] [Code] We investigate the data, paradigms, models, and evaluation protocols for humans interacting with multiple objects. |
|
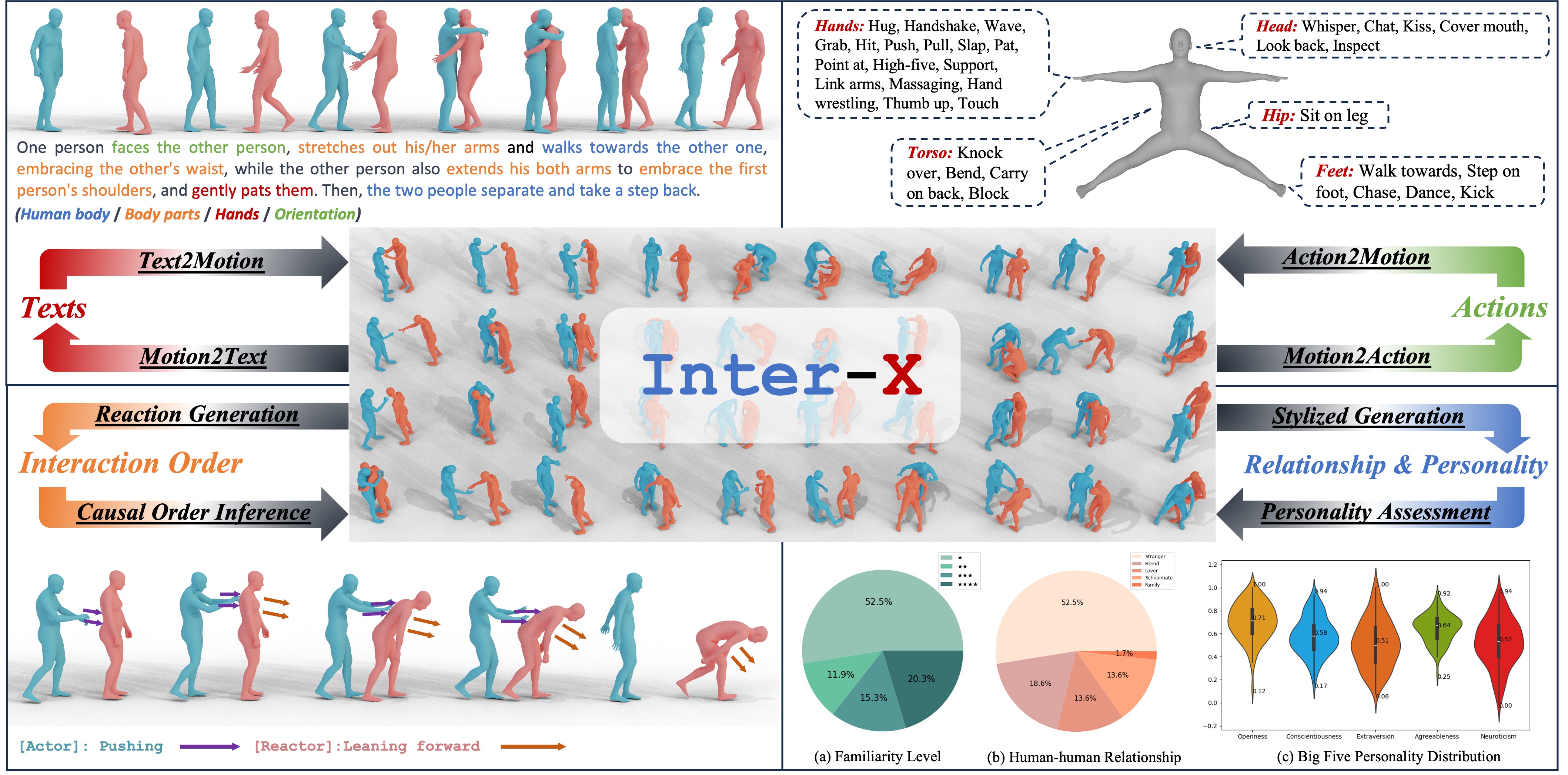
Inter-X: Towards Versatile Human-Human Interaction Analysis
Liang Xu, Xintao Lv, Yichao Yan, Xin Jin, Shuwen Wu, Congsheng Xu, Yifan Liu, Yizhou Zhou, Fengyun Rao, Xingdong Sheng, Yunhui Liu, Wenjun Zeng, Xiaokang Yang CVPR, 2024 [Paper] [Project] [Code] We propose Inter-X, a large-scale dataset of human-human interactions with 11K interaction sequences and more than 8.1M frames with a diverse set of downstream tasks to systematically evaluate human-human interaction capabilities. |
|
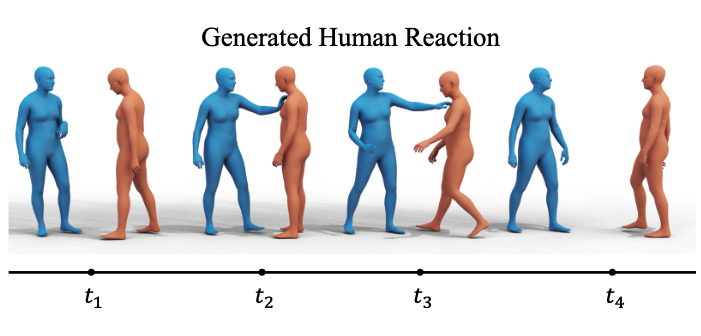
ReGenNet: Towards Human Action-Reaction Synthesis
Liang Xu, Yizhou Zhou, Yichao Yan, Xin Jin, Wenhan Zhu, Fengyun Rao, Xiaokang Yang, Wenjun Zeng CVPR, 2024 [Paper] [Project] [Code] We propose the first multi-setting human action-reaction synthesis benchmark to generate human reactions conditioned on given human actions. |
|
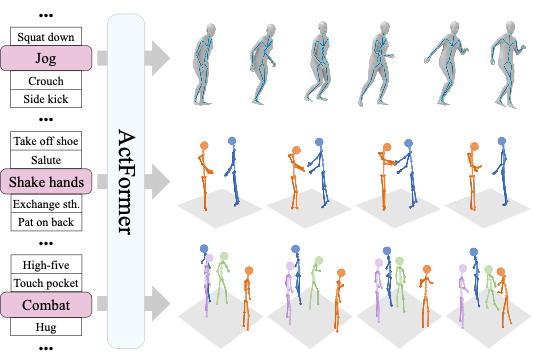
ActFormer: A GAN-based Transformer towards General Action-Conditioned 3D Human Motion Generation
Liang Xu*, Ziyang Song*, Dongliang Wang, Jing Su, Zhicheng Fang, Chenjing Ding, Weihao Gan, Yichao Yan, Xin Jin, Xiaokang Yang, Wenjun Zeng, Wei Wu ICCV, 2023 [Paper] [Project] [Code] We present a GAN-based Transformer for general action-conditioned 3D human motion generation, including single-person and multi-person interactive actions. |
|
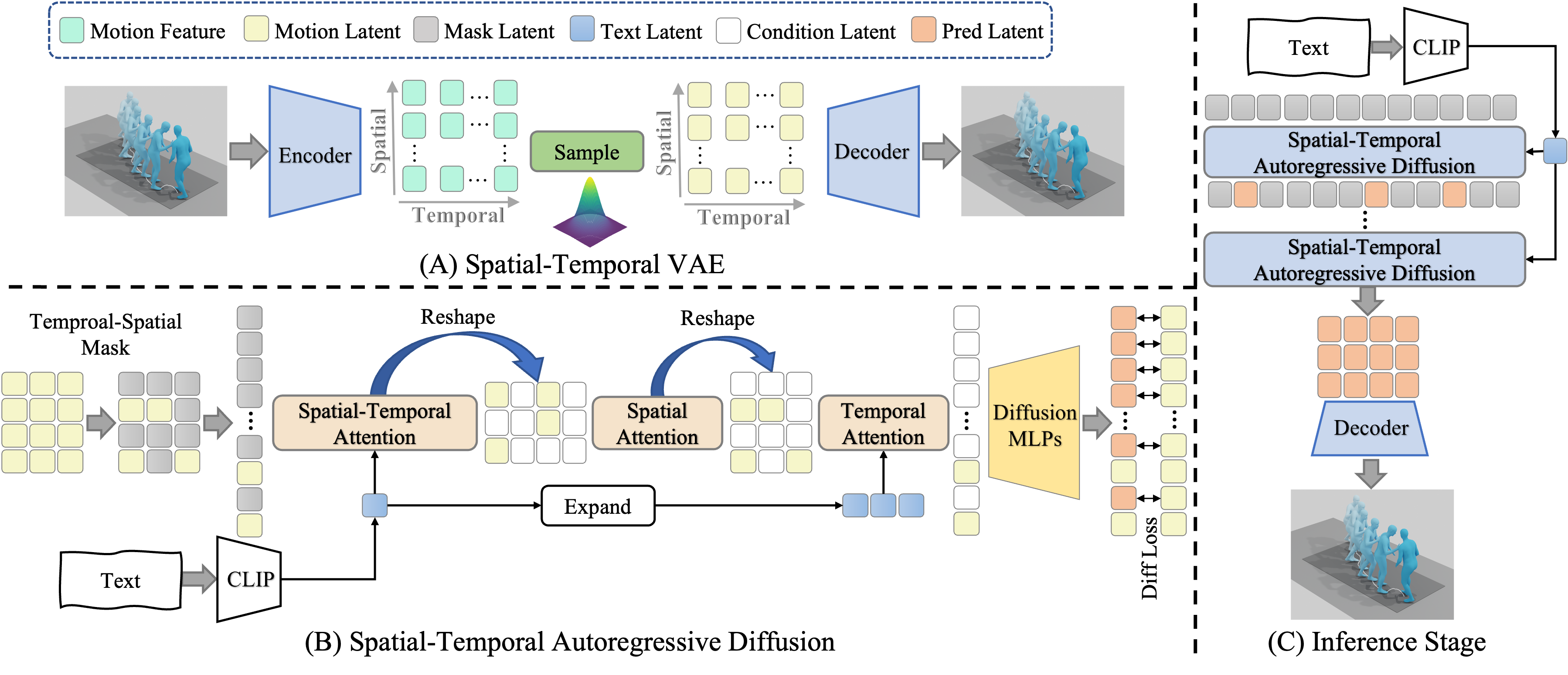
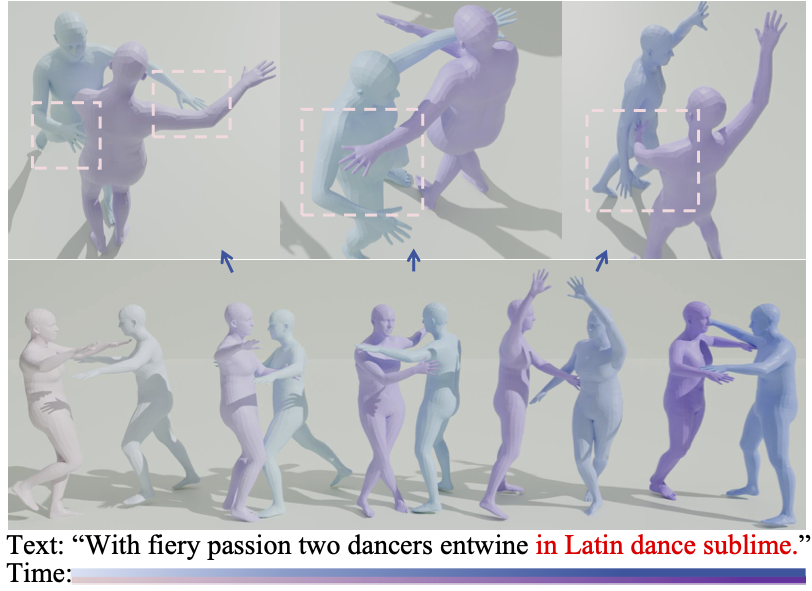
Chengqun Yang, Liang Xu, Yanping Li, Fulong Liu, Jingnan Gao, Weili Zeng, Yichao Yan ICME, 2026 We propose a unified spatiotemporally decoupled framework named DeMoDiff with spatial-temporal VAE for motion representation and spatial-temporal autoregressive diffusion model for motion generation. |
|
Nan Lei, Yuan-Ming Li, Ling-An Zeng, Liang Xu, Zhi-Wei Xia, Hui-Wen Huang, Wei-Shi Zheng ICASSP, 2026 We propose a general-purpose and computationally efficient optimization strategy named PhysiGen to explicitly integrate collision-aware physical constraints for human-human interaction generation. |
|
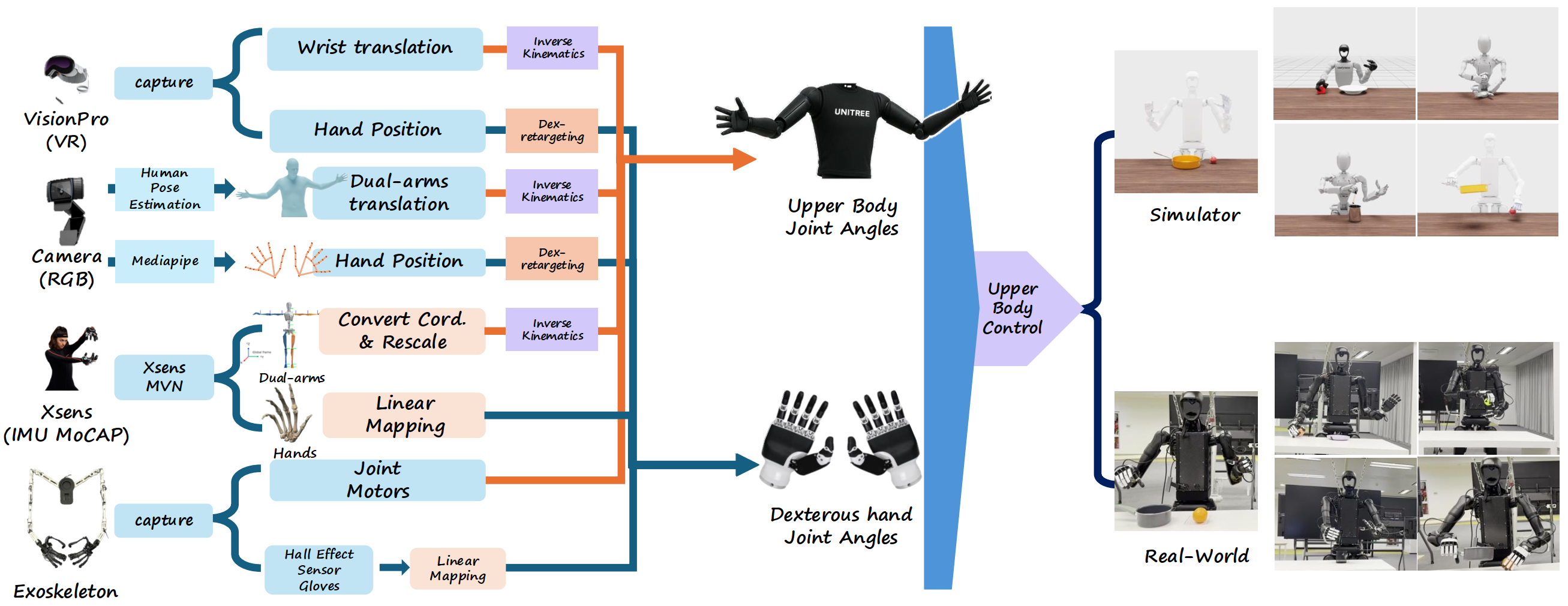
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation
Hangyu Li*, Qin Zhao*, Haoran Xu, Xinyu Jiang, Qingwei Ben, Feiyu Jia, Haoyu Zhao, Liang Xu, Jia Zeng, Hanqing Wang, Bo Dai, Junting Dong, Jiangmiao Pang arXiv, 2025 [Paper] [Project] [Code] We introduce TeleOpBench for benchmarking dual-arm dexterous teleoperation, which integrates motion-capture, VR controllers, upper-body exoskeletons, and vision-only teleoperation pipelines within a single modular framework. |

|
MotionBank: A Large-scale Video Motion Benchmark with Disentangled Rule-based Annotations
Liang Xu, Shaoyang Hua, Zili Lin, Yifan Liu, Feipeng Ma, Yichao Yan, Xin Jin, Xiaokang Yang, Wenjun Zeng arXiv, 2024 [Paper] [Code] We tackle the problem of how to build and benchmark a large motion model with video action datasets and disentangled rule-based annotations. |
|
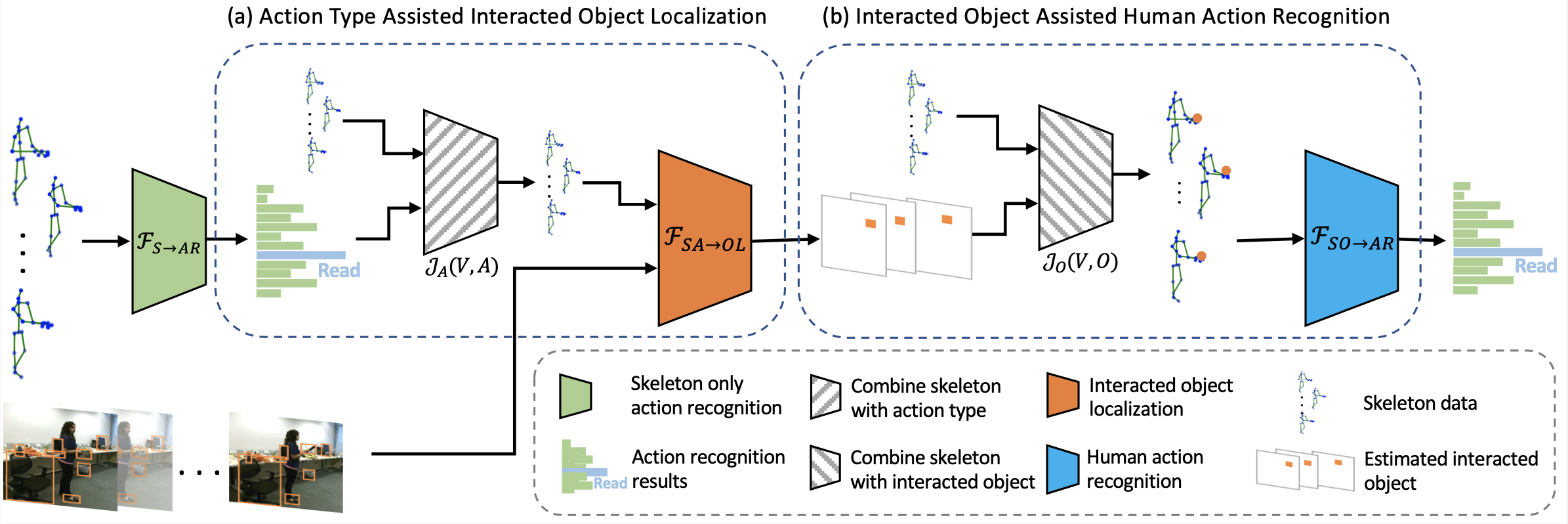
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Liang Xu, Cuiling Lan, Wenjun Zeng, Cewu Lu TMM, 2022 [Paper] We propose a joint learning framework for mutually assisted interacted object localization and human action recognition based on skeleton data. |
|
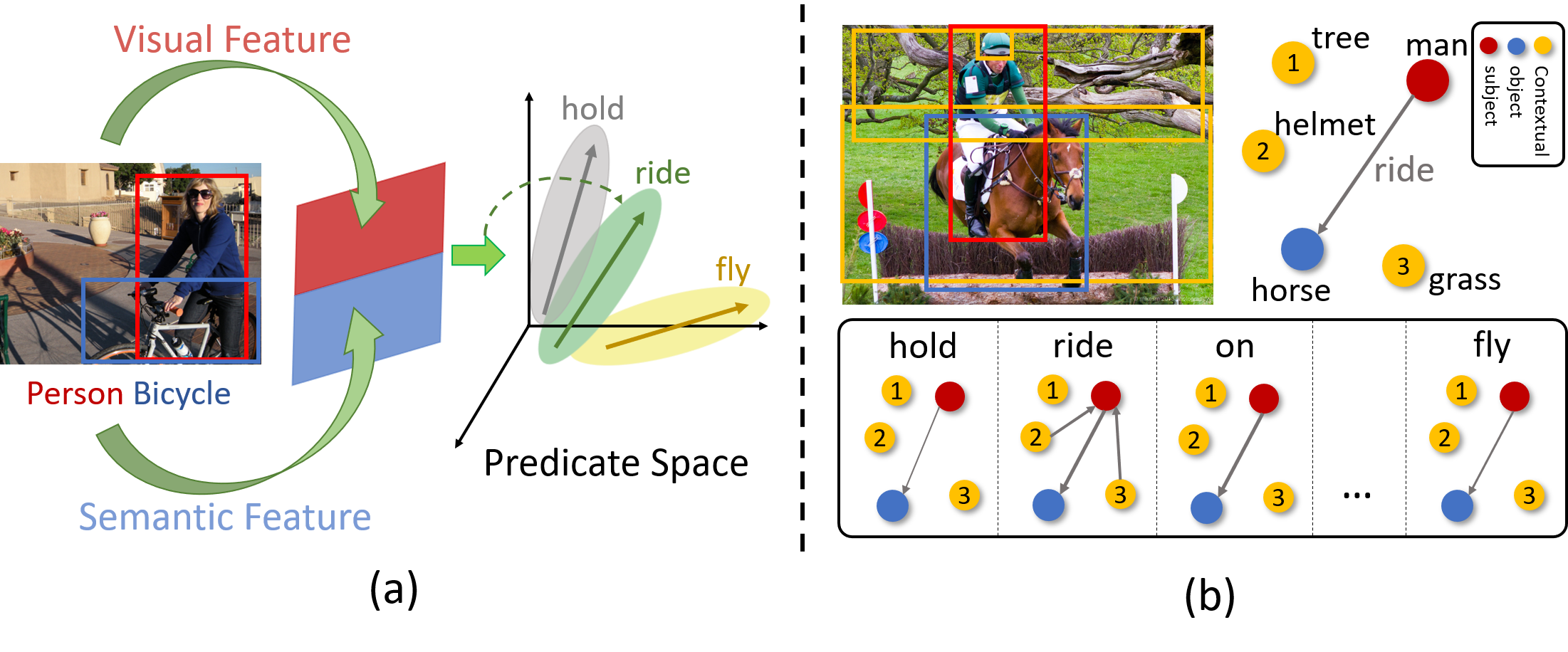
PAL-Net: Predicate-Aware Learning Network for Visual Relationship Recognition
Liang Xu, Yong-Lu Li, Mingyang Chen, Yan Hao, Cewu Lu ICME, 2021 (Oral Presentation) We propose a novel and concise perspective called "predicate-aware learning network (PAL-Net)" for visual relationship recognition. |
|
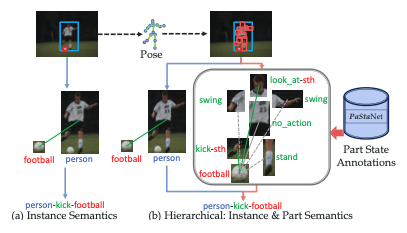
PaStaNet: Toward Human Activity Knowledge Engine
Yong-Lu Li, Liang Xu, Xinpeng Liu, Xijie Huang, Yue Xu, Shiyi Wang, Hao-Shu Fang, Ze Ma, Mingyang Chen, Cewu Lu CVPR, 2020 TPAMI, 2023 [Paper] [Code] [Project] We build a large-scale knowledge base PaStaNet with 7M+ PaSta annotations. We infer PaStas first and then reason out the activities based on part-level semantics. |

|
Transferable Interactiveness Prior for Human-Object Interaction Detection
Yong-Lu Li, Siyuan Zhou, Xijie Huang, Liang Xu, Ze Ma, Hao-Shu Fang, Yan-Feng Wang, Cewu Lu CVPR, 2019 TPAMI, 2022 [Paper] [Code] We explore Interactiveness Knowledge which indicates whether human and object interact with each other or not for Human-Object Interaction (HOI) Detection. |
|
Experience
Shanghai Jiao Tong University & Eastern Institute of Technology, Ningbo, Shanghai/Ningbo, China
Shanghai Artificial Intelligence Laboratory, Shanghai, China
WeChat, Tencent Inc., Beijing, China
SenseTime Technology Development Co., Ltd., Shanghai, China
Microsoft Research Asia, Beijing, China
Shanghai Jiao Tong University, Shanghai, China
Nanjing University, Nanjing, China
|
|
Service
Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, SIGGRAPH, ACM MM, BMVC, IJCV, TMM, WACV |
|
|