We present a GAN-based Transformer for general action-conditioned 3D human motion generation, including not only single-person actions but also multi-person interactive actions.
Our approach consists of a powerful Action-conditioned motion TransFormer (ActFormer) under a GAN training scheme, equipped with a Gaussian Process latent prior. Such a design combines the strong spatio-temporal representation capacity of Transformer, superiority in generative modeling of GAN, and inherent temporal correlations from the latent prior. Furthermore, ActFormer can be naturally extended to multi-person motions by alternately modeling temporal correlations and human interactions with Transformer encoders. To further facilitate research on multi-person motion generation, we introduce a new synthetic dataset of complex multi-person combat behaviors.
Extensive experiments on NTU-13, NTU RGB+D 120, BABEL and the proposed combat dataset show that our method can adapt to various human motion representations and achieve superior performance over the state-of-the-art methods on both single-person and multi-person motion generation tasks, demonstrating a promising step towards a general human motion generator.
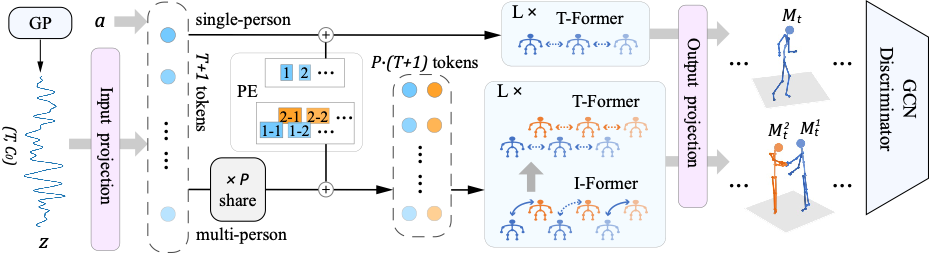
Given a latent vector sequence z sampled from Gaussian Process (GP) prior and an action label a, the model can synthesize either a single-person (top stream) or a multi-person (bottom stream) motion sequence. For the multi-person motions, Actformer alternately models temporal correlations (T-Former) and human interactions (I-Former) with Transformer encoders. The model is trained under a GAN scheme.
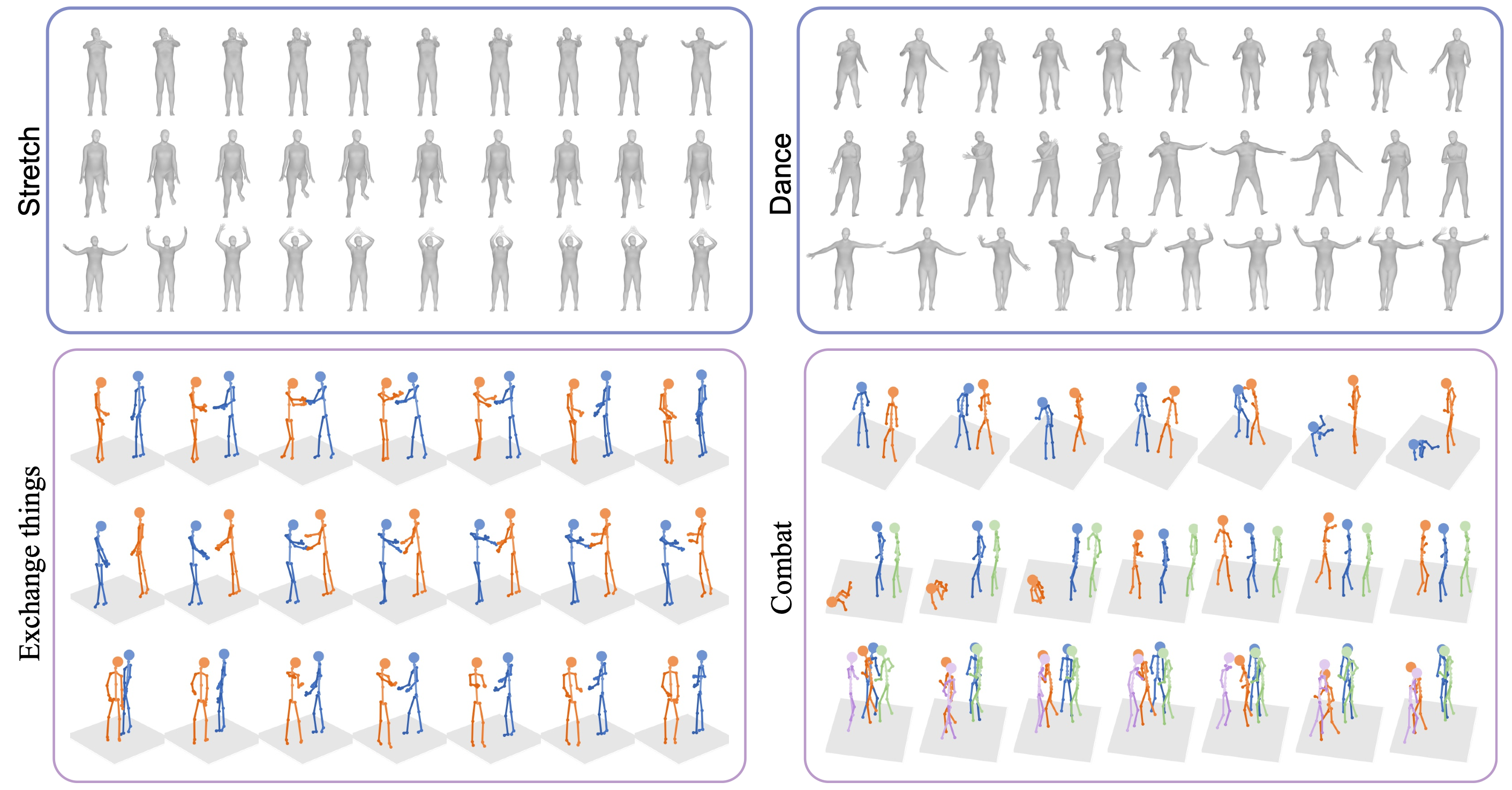
To facilitate the research on multi-person motion generation, we construct a GTA Combat dataset through the Grand Theft Auto V's gaming engine. In this synthetic multi-person MoCap dataset, we collect (~7K) combat motion sequences each with 2 to 5 participants. Here are samples from our dataset. (Note that, only the persons involved in the combat behavior are useful parts from the rgb data, and the irrelevant others could be neglected.)
Download the GTA Combat dataset from here.
@article{xu2023actformer,
author = {Xu, Liang and Song, Ziyang and Wang, Dongliang and Su, Jing and Fang, Zhicheng and Ding, Chenjing and Gan, Weihao and Yan, Yichao and Jin, Xin and Yang, Xiaokang and Zeng, Wenjun and Wu, Wei},
title = {ActFormer: A GAN-based Transformer towards General Action-Conditioned 3D Human Motion Generation},
journal = {ICCV},
year = {2023},
}