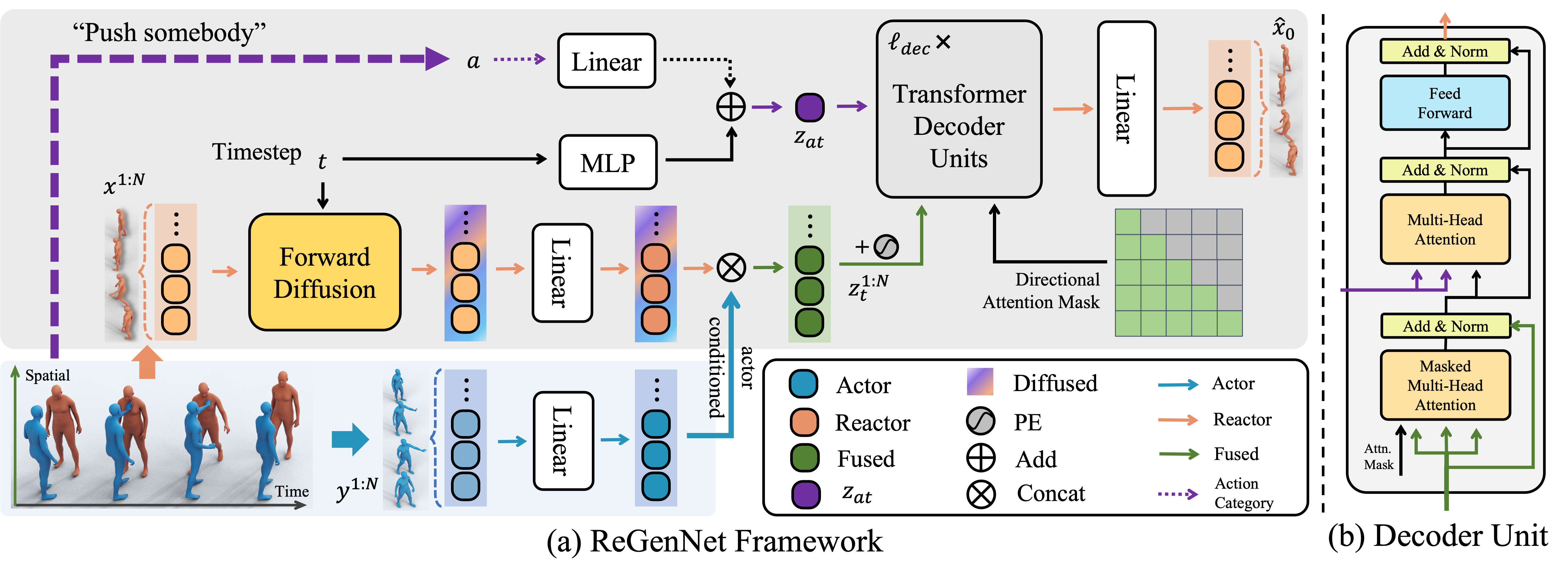
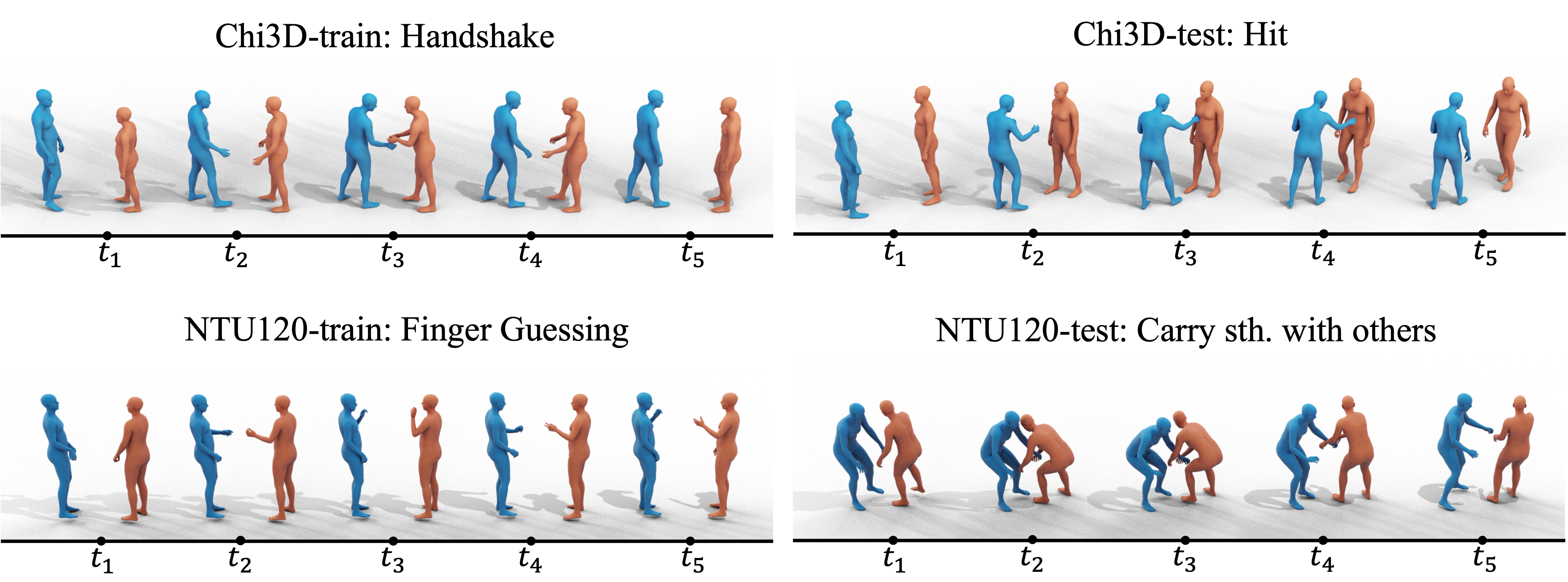Humans constantly interact with their surrounding environments. Current human-centric generative models mainly focus on synthesizing humans plausibly interacting with static scenes and objects, while the dynamic human action-reaction synthesis for ubiquitous causal human-human interactions is less explored. Human-human interactions can be regarded as asymmetric with actors and reactors in atomic interaction periods. In this paper, we comprehensively analyze the asymmetric, dynamic, synchronous, and detailed nature of human-human interactions and propose the first multi-setting human action-reaction synthesis benchmark to generate human reactions conditioned on given human actions. To begin with, we propose to annotate the actor-reactor order of the interaction sequences for the NTU120, InterHuman and Chi3D datasets. Based on them, a diffusion-based generative model with a Transformer decoder architecture called ReGenNet together with an explicit distance-based interaction loss is proposed to predict human reactions in an online manner, where the future states of actors are unavailable to reactors. Quantitative and qualitative results show that our method can generate instant and plausible human reactions compared to the baselines, and can generalize to unseen actor motions and viewpoint changes.